Together AI
Together fine-tunes / batch jobs - completion without polling.
Together AI's outbound webhook system is still in private preview, so the cleanest path today is in-process: wrap your fine-tune submission with `chirp.activity` and stream Together's job events into the activity's `update()` method. Same shape as the Modal walkthrough - the difference is you're tailing Together's event stream instead of looping over your own batches.
Once Together ships native outbound webhooks, this integration will switch to the @huggingface model (paste a URL in their dashboard). The current SDK-based pattern keeps working either way - Chirp's @together schema accepts both.
Prerequisites
- A Together account + `TOGETHER_API_KEY`.
- Chirp Python SDK (`pip install chirp-sdk`) + `chirp login` locally.
Setup
- 1
Install both SDKs
Together's SDK plus Chirp's SDK. Both are pure-Python, no native deps.
shellpip install together chirp-sdk - 2
Pair Chirp
chirp loginonce on the laptop running the script. Drops credentials at~/.chirprc. The SDK reads them automatically.shellchirp login - 3
Wrap the fine-tune with chirp.activity
Open the activity on submission, stream Together's events, close on context exit. Together's
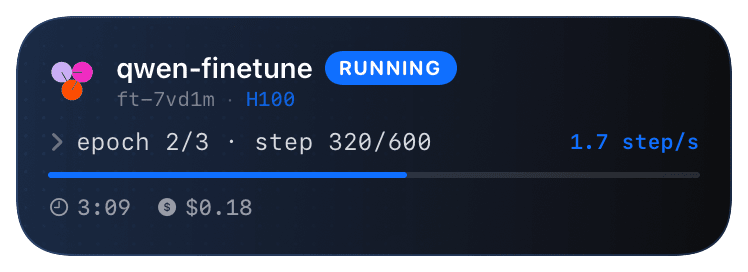
list_events(stream=True)blocks until the job terminates, which lines up perfectly with the activity's lifecycle.together_job.pyimport chirp from together import Together client = Together() with chirp.activity("@together", { "jobName": "qwen-finetune", "gpuType": "H100", "model": "Qwen/Qwen2.5-7B", }) as a: job = client.fine_tuning.create( model="Qwen/Qwen2.5-7B", training_file="file-abc123", n_epochs=3, ) a.update({"stageNote": "submitted", "jobId": job.id}) for ev in client.fine_tuning.list_events(id=job.id, stream=True): a.update({"stageNote": ev.message}) # Optional: parse progress from ev.message and pass it along. # Context manager closes the card on exit (green if no exception). - 4
(Optional) Run from a long-lived script with retries
If your fine-tune script lives on a server (not your laptop), run it under tmux or as a systemd unit. The activity continues across SSH disconnects since it's the *server* that holds the activity token.
What you’ll see
Card header: Together logo + "Together · TRAINING" + jobName. Action line shows GPU type + current stage from Together's event stream ("queued", "loading data", "epoch 1/3", etc.). Closes green on clean exit; red with the exception on raise. If your script crashes mid-job, the activity will hang at the last update - restart the script and pass the same `jobName` to coalesce on the existing card.
Troubleshooting
- list_events hangs forever even though the job is done.
- Together's stream sometimes doesn't emit a terminal event when the job completes via the dashboard's "cancel" button. Set a timeout:
for ev in client.fine_tuning.list_events(id=job.id, stream=True, timeout=30):and break manually ifclient.fine_tuning.retrieve(job.id).statusis terminal. - Card opens with no GPU type.
- GPU type isn't in Together's event payload - pass it manually based on which model you're tuning. Reference: 7B → A100, 70B → H100. The schema renders the value verbatim.
- I want to use this for batch inference, not fine-tunes.
- Same pattern, swap
client.fine_tuning.createforclient.batches.createand tailclient.batches.retrieve(batch.id)in a polling loop. The @together schema renders "BATCH" instead of "TRAINING" whenkind: "batch"is passed.